Quando negli anni ’50 del secolo scorso Francis Crick e James D. Watson (insieme alla sempre dimenticata Rosalinda Franklin) scoprirono per la prima volta la struttura a doppia elica del DNA, lo stesso Crick formulò quello che è stato definito il dogma centrale della biologia molecolare. Secondo tale dogma, che non è da intendersi in senso assoluto ma piuttosto come principio della biologia molecolare, il flusso dell’informazione genetica è monodirezionale, cioè parte dagli acidi nucleici (DNA e RNA) per arrivare alle proteine.
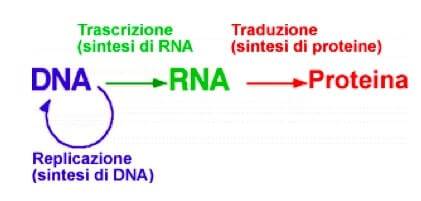
L’informazione contenuta nel DNA deve essere innanzitutto in grado di replicarsi affinché sia conservata e trasmessa da una generazione cellulare a quella successiva. Inoltre, le informazioni contenute nel DNA sono necessarie alla sintesi delle proteine. Per questo esse sono prima trascritte in un tipo particolare di RNA, detto RNA messaggero (mRNA) e infine tradotte in proteine.
Il codice genetico è il codice che permette di trasformare una sequenza di nucleotidi (i monomeri di base degli acidi nucleici) in una sequenza di amminoacidi (i monomeri di base delle proteine).
Le caratteristiche
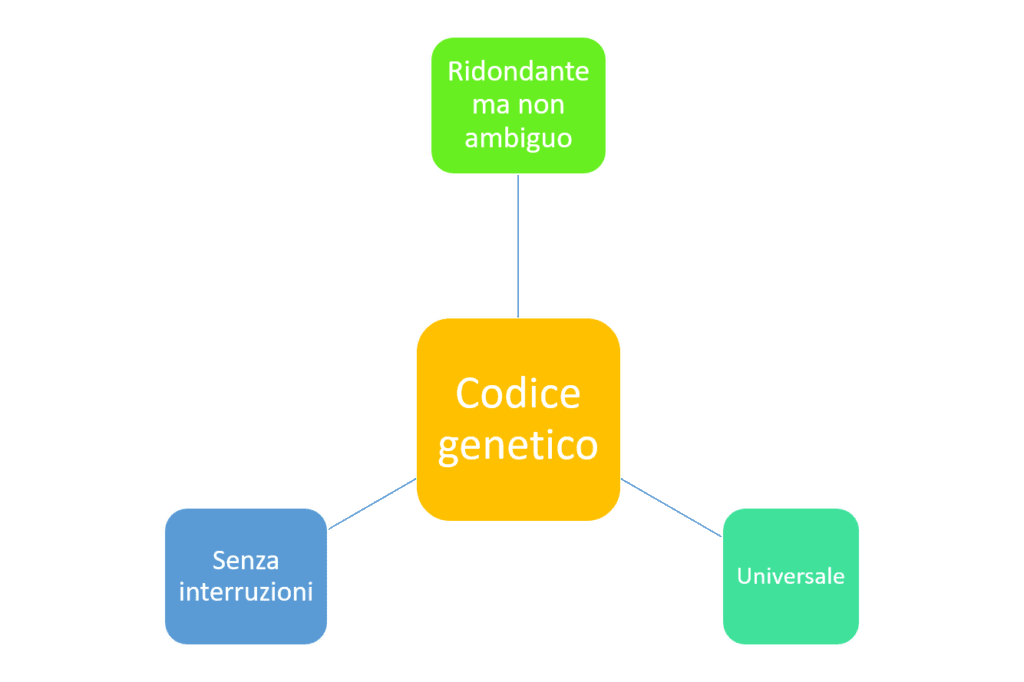
Il codice genetico presenta alcune caratteristiche ben definite, riassunte dal seguente schema.
La decifrazione
Quando i biologi hanno tentato di decifrare il codice genetico, e cercato di capire come la sequenza di nucleotidi si trasformi in una sequenza di amminoacidi, hanno inizialmente ipotizzato che ogni nucleotide codificasse per un singolo amminoacido. Tuttavia, gli amminoacidi esistenti nella struttura delle proteine sono 20. I nucleotidi che costituiscono gli acidi nucleici sono 4 (differenziati in base al tipo di base azotata che contengono). Secondo questa ipotesi, dunque, il codice genetico avrebbe codificato solo per 4 amminoacidi.
Andando per tentativi, se due nucleotidi avessero codificato per un amminoacido, le possibili combinazioni sarebbero state 16, ancora troppo poche. Se invece si ipotizza che tre nucleotidi codifichino per un amminoacido, si avranno in totale 64 combinazioni. Un tale numero di combinazioni è sufficiente per codificare i 20 amminoacidi, anzi, è ridondante.
La decifrazione del codice genetico si deve a Marshall W. Nirenberg, vissuto tra il 1927 ed il 2010 e considerato uno dei maggiori biologi molecolari dei nostri tempi.
Il codice genetico è ridondante ma non ambiguo
Definire il codice genetico ridondante vuol dire ammettere che alcuni amminoacidi siano codificati da triplette diverse. Le triplette che codificano lo stesso amminoacido sono in genere molto simili e differiscono solo per l’ultima delle tre basi. Una tripletta di nucleotidi prende il nome di codone e ogni codone codifica per un amminoacido. Tre di queste triplette, definite triplette non senso, non codificano per nessun amminoacido ma servono a segnalare la fine della catena proteica. Esse sono: UAG, UAA, UGA. La tripletta AUG, che codifica per l’amminoacido metionina (o per la formilmetionina nei batteri), indica invece l’inizio della catena proteica. La metionina e il triptofano, codificato dalla tripletta UGG, sono gli unici due amminoacidi ad essere codificati da un singolo codone.
La ridondanza del codice genetico lo rende meno vulnerabile alle mutazioni casuali. Un codone quattro volte ridondante (in cui qualsiasi nucleotide nella terza posizione codifica lo stesso amminoacido) può subire qualsiasi mutazione alla sua terza posizione senza che l’amminoacido da esso espresso (e di conseguenza la proteina sintetizzata) cambi.

Il codice genetico è ridondante ma non ambiguo. Non è ambiguo perché, sebbene uno stesso amminoacido possa essere codificato da diverse triplette, nessuna tripletta codifica per più di un amminoacido.
Il codice genetico è continuo ed universale
Altre due caratteristiche fondamentali del codice genetico sono la continuità e l’universalità.
Il codice genetico è continuo, ovvero non ha segni di interpunzione. L’mRNA viene letto in gruppi successivi di triplette senza saltare nessun nucleotide. Inoltre, non ha sovrapposizioni, cioe ogni nucleotide appartiene ad una sola tripletta e il nucleotide finale di un codone, ad esempio, non può essere letto come il nucleotide iniziale del codone successivo. Nei virus, tuttavia, possiamo trovare geni sovrapposti: due o più geni nei quali un gene, tutto o in parte, è contenuto nell’altro. Questa caratteristica si ritrova abbastanza frequentemente nei genomi di dimensioni molto piccole e ha lo scopo di aumentarne l’efficienza.
Infine il codice genetico è universale, in quanto tutti i codici genetici noti presenti nelle forme di vita della Terra sono molto simili ed il meccanismo di codifica è lo stesso per tutti gli organismi. In realtà, grazie alle scoperte di lievi variazioni del codice standard iniziate nel 1979, oggi sarebbe più corretto definire il codice genetico quasi universale. Ecco alcuni esempi di varianti che possiamo trovare:
- la traduzione del codone UGA a triptofano nelle specie di Mycoplasma
- la traduzione di CUG come una serina piuttosto che una leucina in alcuni lieviti tra cui la Candida albicans
- GUG e UUG come codoni di inizio nei batteri e negli archeobatteri
- UAG e, spesso, UAA che codificano la glutammina nei protozoi ciliati e in alcune alghe mentre UGA codifica la cisteina
- i codoni di arresto che codificano amminoacidi non comuni in altre specie di batteri e archeobatteri
- molte variazioni sono state osservate nel codice mitocondriale
Fonti:
- https://it.wikipedia.org/wiki/Codice_genetico
- https://www.chimica-online.it/
- https://www.sapere.it/
- Elzanowski A e Ostell J, The Genetic Codes, su ncbi.nlm.nih.gov, National Center for Biotechnology Information (NCBI), 7 aprile 2008
- Santos MA e M.F. Tuite, The CUG codon is decoded in vivo as serine and not leucine in Candida albicans, in Nucleic Acids Research, vol. 23, n. 9, 1995, pp. 1481-6, DOI:10.1093/nar/23.9.1481, PMC 306886, PMID 7784200.
Il Caduceo è simbolo di longevità e immunità